Where should I start if I want to try out or run ZITADEL?

Dev Ops Engineer
Introduction
As you have seen from the first part, ZITADEL runs on Kubernetes. You can use any available cluster with the minimal requirements needed to run ZITADEL (SMTP, SMS-Service, Database, Domain), and get started quickly with ZITADELCTL. Use ORBOS, maybe tailored to use your favorite tools, to automate most of the infrastructure and tools.
Where the goal of the first part of this article was to give you some guidance where to start with try or run ZITADEL on your own, in this sequel I want to give you some more insight how we run our ZITADEL SaaS.
Our current infrastructure & tools
The current infrastructure is centered around locations in Switzerland and for this we use GCE’s compute instances to then manage everything on top through our product ORBOS.
As the following components are changeable and this is just our preferred toolset, if anyone needs or wants to use something different, this should be possible without any issues, just ignore our recommendations.
So we have the managed VMs, we use the combination NGINX and firewalld to handle connections on the node and routing outside the cluster, Kubernetes with Calico, Ambassador inside the cluster with NodePorts to provide connectivity and routing on the inside. Backups are currently made to Google Storage Buckets with CockroachDB native full backups, which makes the restore functionality easier to maintain. To hold metrics and logs to conveniently operate ZITADEL or any other tool we use, there also runs Loki and Prometheus inside the cluster and the visualization and alerting is possible through Grafana. We also use some operators that help us to maintain our tools, but maybe this will be a topic for another post.
Why our Stack
So to just visualise our stack that was described in the section before:
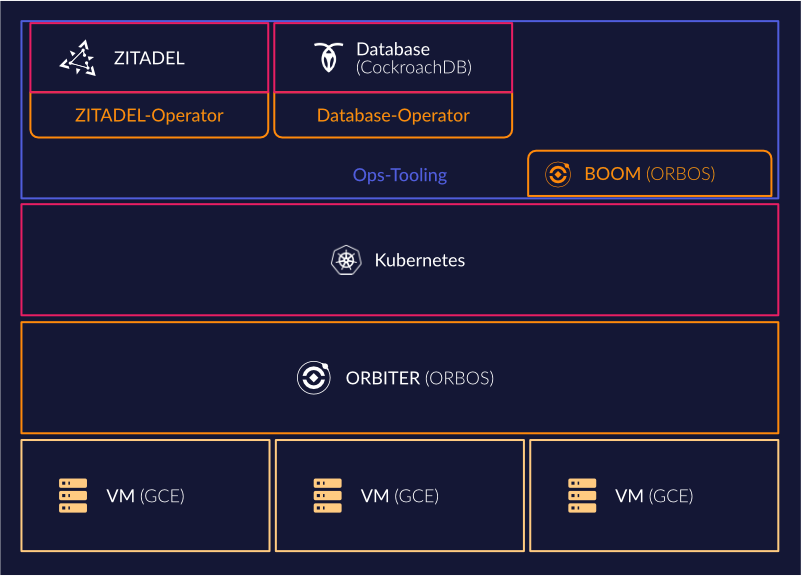
As base we use VMs of the Google Cloud Engine because we can limit the region and zones so that we can hold our data still in Switzerland but at the same time we can use multiple zones for high availability. The usage of other hyperscalers where you can limit the resources to Switzerland would also be possible, but as we had prior experience and it covered everything we needed, we decided to go with Google Cloud initially.
We decided to make our own Kubernetes automation to provide a platform as a decentralised solution in combination with the advantages of Kubernetes, the usage of already available and tested tools and possibilities of GitOps.
As we want to use already existing tools, one part of ORBOS is the deployment of a set of tools in defined versions with additional integration of the components themselves, for example the scraping of all metrics of the toolset. The result is that there exists one file that contains all necessary configuration for the whole toolset.
Which results in a constellation on the cluster as follows:
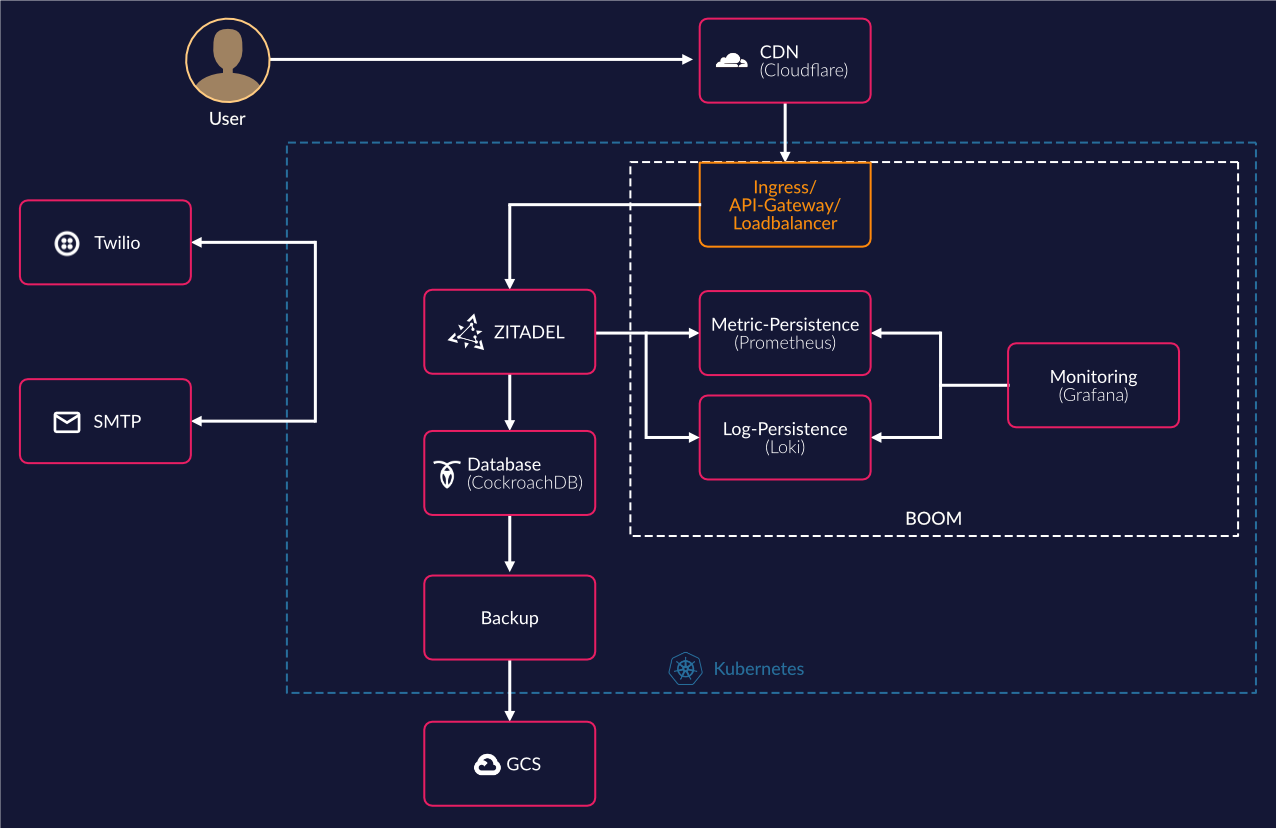
As our CDN/DNS we use Cloudflare to register subdomains and define firewall-rules, the connections to the subdomains end up on the Ambassador in-cluster and will get routed to the ZITADEL pods. The database we currently use is CockroachDB, as mentioned before, and all backups are made into a Google Cloud Bucket.
For monitoring and alerting we use the combination of Loki (log persistence), Prometheus (metrics persistence) and Grafana (visualisation and alerting) as this combination is widespread and battle-tested, this components could be changed to other solutions but for our goal to be decentralized and low resource consumption we are really comfortable.
Planned changes in the near future
To further improve the functionality of ORBOS we have different things in the pipeline. One of these is the possibility to use VMs of different zones on Google Cloud to have more options to provide high availability, another is the addition of different implementations of storage options to use for backups. As well as improvements on our own tooling, the current used version for Kubernetes and the used tools will get routinely updated and moved to the newest version. The operators will get new releases as well as the IAM gets new releases, where the operators will as mentioned self-reconcile if you just change the version in the configuration.
Make or buy?
As you just read and also see in our other blog post “Always run a changing system - The CAOS approach” we are all for it to use already implemented tools to make our work easier, but we automate everything we can so we don’t have to do thing multiple times by hand. At the same time we also have to maintain our own code with new releases from the used tooling.
There are advantages and disadvantages to this pattern, but currently the advantages overweigh. As you say “horses for courses”, we use tooling for tasks that are uniformly done for applications, but provide operators for tasks that are specific to ZITADEL, which also integrate the tools with each other.